-
[Machine Learning] 최대우도법(Maximum Likelihood Estimation)Informatik 2022. 2. 9. 21:13
최대우도법은 어떤 확률 변수(Random Variable)에서 표집한 값들을 토대로 그 확률 변수의 모수(Parameter)를 구하는 방법이다. 어떤 모수가 주어졌을 때, 원하는 값들이 나올 우도(Likelihood)를 최대로 만드는 모수를 선택한다. [wikipedia]
평균(Mean)이나 공분산(Covariance)으로 이루어진 모수 벡터(Parameter Vector)
- 데이터 세트(Dataset)
- 데이터의 각 예시
- 결합 확률 밀도 함수(Joint Density Function)는 다음과 같다.
※ 편리성을 위해,Q. 우도 대신 로그 우도를 대신 구하는 이유는?
A.
따라서 최적의 모수를 찾는 MLE는 다음의 식과 같다.
예시 1) 오류가 가우시안 분포(Gaussian Distribution)를 따를 때(
위의 모델
학습 예시

위의 그림에서 MLE로 최적의 가설을 찾는 것은 MSE를 최소화하는 것과 같음을 증명한다.
예시 2) 정규 분포(
해당 모델의 데이터
모든 데이터들이 독립적으로 생성되었다는 가정하에 결합 우도와 로그 우도는 다음과 같다.
예시 3) 다변량 정규분포(Multivariate Normal Distribution) (
다변량 정규분포의 확률 밀도 함수(Multivariate Normal Distribution pdf):

다변량 정규분포의 평균값 추정 
다변량 정규분포의 공분산 추정
예시 4) 베루누이 분포(Bernoulli Distribution)
데이터
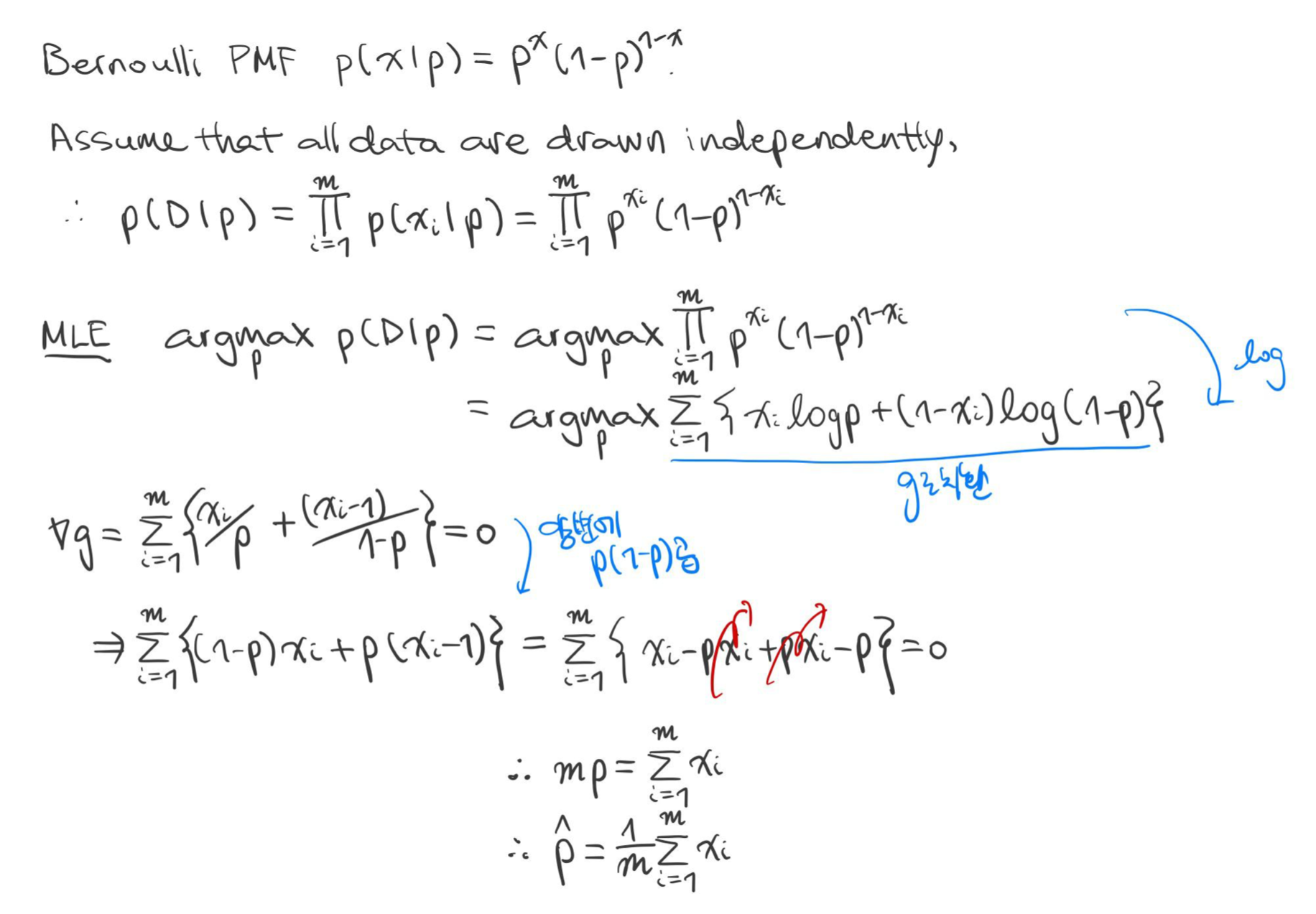
예시 5)
위의 확률 분포를 따르는 데이터 세트
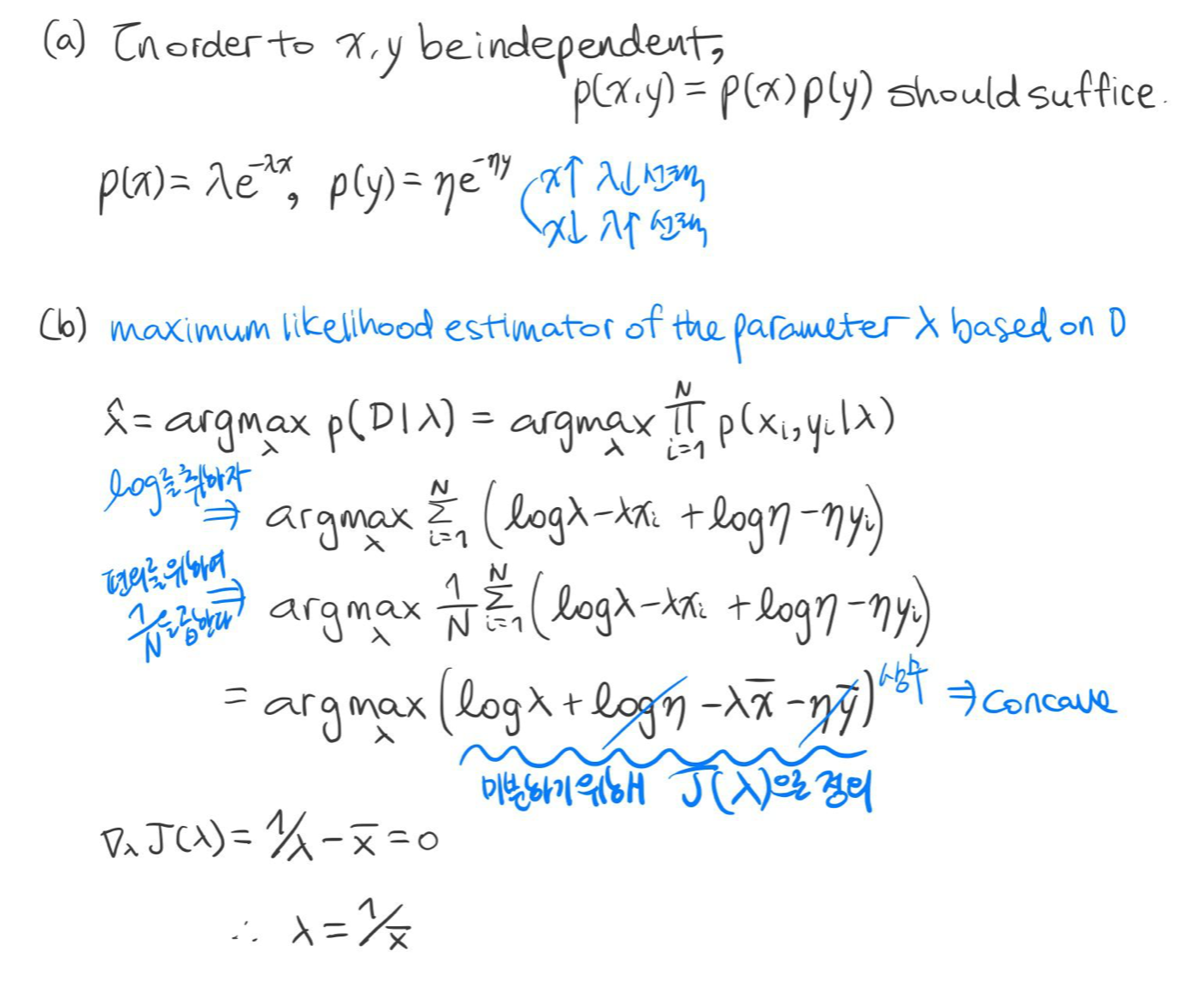

예 6) 기하 분포(Geometric Distribution)
아래의 그림은 기하 분포를 따르는 데이터를 두 클래스
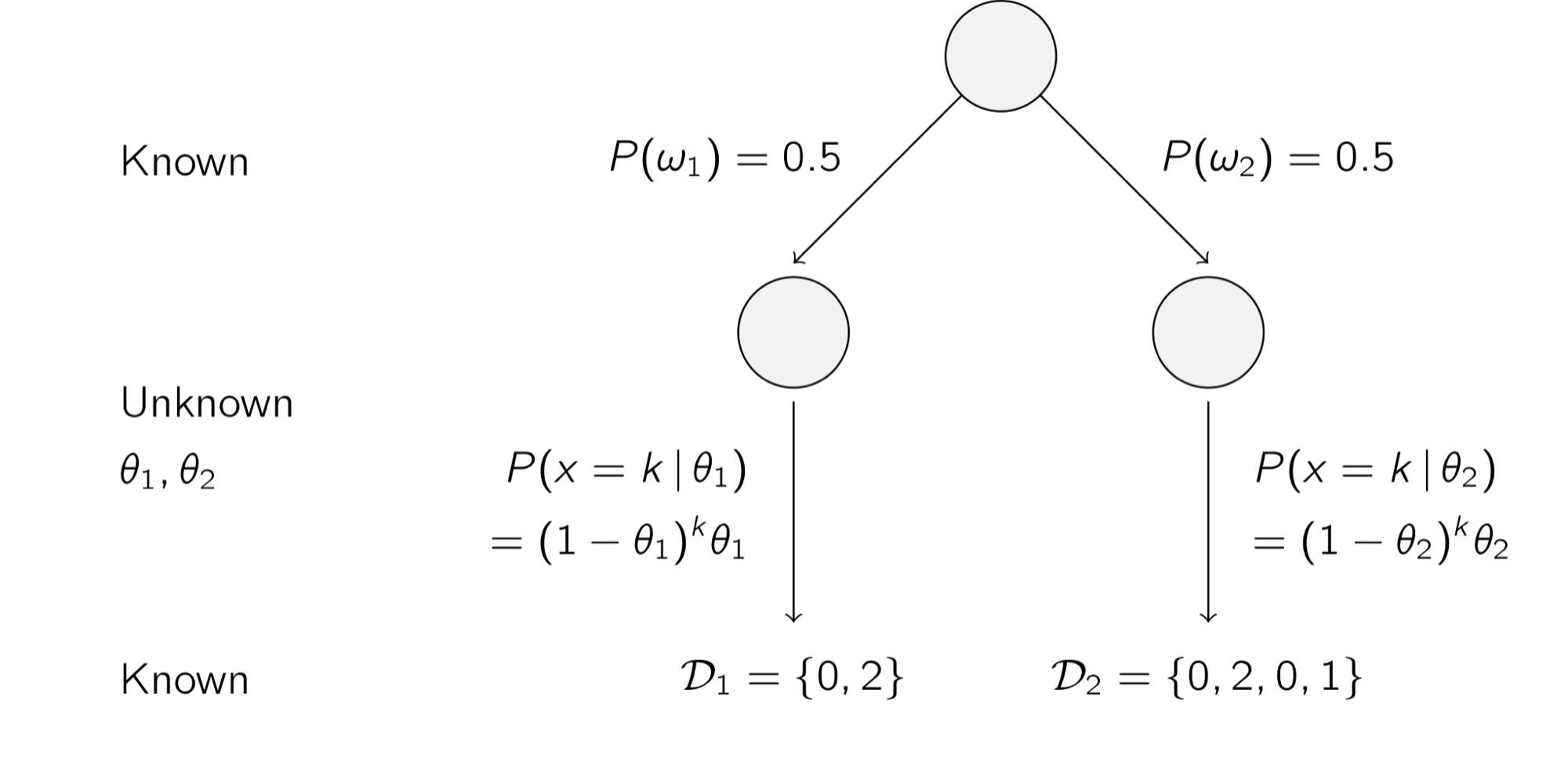

k = 1일 때의 분류기 예시 이처럼 MLE를 이용해 알려지지 않은 확률 분포 모수를 예측할 수 있으며, 예측한 모수에 베이즈 이론을 적용해 데이터를 분류한다.
'Informatik' 카테고리의 다른 글
[Machine Learning] 다중 선형 회귀(Multiple Linear Regression) (0) 2022.02.12 [Machine Learning] 경사 하강법(Gradient Descent) (0) 2022.02.09 [Machine Learning] PCA(Principal Component Analysis) (0) 2022.02.09 [Machine Learning] 최대우도법 vs. 베이즈 추정법(Maximum Likelihood Estimation vs. Bayesian Estimation) (0) 2022.01.31 [Machine Learning] 단순 선형 회귀(Simple Linear Regression) (0) 2022.01.28 - 데이터 세트(Dataset)
